Personal Blog
Flagship Project
Clinical Decision Support System for Diagnosing Allergy Comorbidities
-
Raw IDST Data: Intradermal skin test (IDST) results, consisting of 92 categorical attributes (allergens and symptoms) and a multi-class label (allergies), are collected from testing centers in South India.
-
Data Partitioning: A stratified hold-out approach is used to divide the raw IDST data into training and testing sets.
-
Data Cleaning: Samples with more than 30% missing values are discarded, while statistical methods are applied to impute the missing values in the remaining samples.
-
Data Sampling: SMOTE (Synthetic Minority Over-sampling Technique) with varying class distributions is used to balance the data, ensuring the underlying distribution is not disrupted.
-
k-fold Cross Validation: Six different machine learning algorithms are trained and validated to assess their generalization performance.
-
Rule Extraction: Random forest is selected as the best-performing classifier based on validation results, and human-readable rules are extracted and stored in a rule base.
-
Expert Assessment: This step ensures that the machine learning model has correctly learned the intended knowledge and accurately captures the relevant patterns.

Results & Conclusion: The Random Forest model achieved an accuracy of 86.39% and a sensitivity of 75% for the comorbid Rhinitis-Urticaria class. The system was evaluated in real-time by clinicians, with average performance improving from 77.21% before using the decision support system to 81.80% after its implementation. This demonstrates that the system can be customized and effectively utilized by clinicians to support their diagnostic decision-making.
Research Topics
Three-way Decision-Making with Prospect Theory
It is important to acknowledge that real-world data is often limited and uncertain. Additionally, in certain situations, multiple decision alternatives may need to be considered (such as in candidate selection during an interview process). To tackle the challenges posed by limited information and an extensive decision space, the three-way decision-making approach is ideal. This method simplifies the decision process by categorizing all possible alternatives into three sets: the acceptance set, rejection set, and uncertain set.
The Three-way Decision Making Model consists of two main phases:
1. Knowledge Engineering: The objective of this phase is to create target models that represent the information provided by each attribute for each decision alternative, based on the available evidential (training) data. These target models can be generated using methods such as kernel functions, fuzzy membership functions, and confidence measures.
2. Decision Making: The goal of this phase is to categorize the possible decision alternatives into three sets—accept, reject, and uncertain—based on the deviation between the computed probability values and estimated reference values. Alternatives in the acceptance set have higher prospects than those in the uncertain set, and alternatives in the uncertain set have higher prospects than those in the rejection set. This approach provides flexibility, allowing multiple decisions to be made for a single, complex decision problem.

Concept Drift Adaption for Achieving Performance Consistency
The world is constantly evolving, and knowledge is continuously expanding. When there are shifts in concepts or data over time, the performance of a machine learning model deployed in the real world may degrade and require updated data to maintain its effectiveness. To address this issue of performance decline, drift adaptation strategies are the most effective solution. These strategies detect the type of drift and analyze future requirements, enabling the model to be retrained as needed.
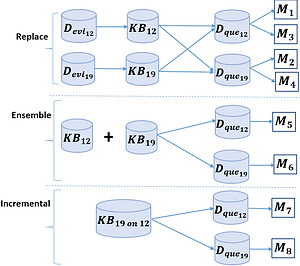
Three drift adaptation strategies—replace, ensemble, and incremental—are proposed to recommend a model from M1 to M8 based on the performance on test datasets with updated knowledge from both old and new training datasets.
1. Replace Strategy: This strategy independently evaluates the knowledge bases of previous evidential data (D_evi_12) and new evidential data (D_evi_19) using both the previous test data (D_test_12) and the new test data (D_test_19).
2. Ensemble Strategy: This strategy combines the knowledge bases of both evidential datasets (KB_12 and KB_19) to evaluate the two test datasets together.
3. Incremental Strategy: This strategy integrates the knowledge of new evidential data with the previous evidential data (KB_19on12) and uses the combined knowledge to evaluate both test datasets.
On-going Project
AI-driven Twin Bot to Assist Humans in Balancing Emotional
Intensities for Efficient Decision-Making
Background & Motivation
Decision-making plays a crucial role in every aspect of human life. However, during important decisions, individuals often experience intense emotions such as overthinking, behavioral regrets, stress, and anxiety. These emotions can lead to poor decision-making, driven by temporary negative feelings, which negatively impacts both the quality of life and the clarity of thought when contemplating future actions.
With advancements in Machine Learning and Artificial Intelligence (AI) in wearable devices, many people now use smart devices to monitor and support both their physical and mental health. However, there is currently no application within these wearable devices that provides context-sensitive alerts and recommendations during critical decision-making situations when negative emotions dominate.
Objective
This project aims to address this gap by developing an AI-driven twin-bot application that can be installed on both mobile devices and wearable smartwatches. The application will assist users in making better decisions by offering focus-based recommendations when intense negative emotions are influencing their decision-making.

Key Features of the AI-driven Twin-bot Framework:
1. AI-driven Activity-based Emotion Recognition Model: This model recognizes basic emotions by analyzing human thought patterns derived from app usage, search history, and meeting schedules.
2. Speech Emotion Recognition Model: This model identifies emotions by analyzing vocal intensity, providing insight into emotional states based on speech patterns.
3. Graph Neural Network for Mixed Emotion Recognition: Unlike existing approaches that focus on specific combinations of emotions, this model recognizes a wide range of mixed emotions by analyzing the intensity of basic emotions. Additionally, it customizes focus aspect recommendations to ensure emotions do not overwhelm the decision-making process, guiding users toward making better choices.
4. User-understandable Explanations for Mental Well-being: The system presents personalized focus aspect recommendations in a manner that avoids exposing emotional shifts, crucial for critical decision-making scenarios. These recommendations are delivered via notifications to the smartwatch and smartphone, with a vibration mechanism to ensure the user receives timely alerts.Live Experiments:To ensure the product effectively supports working professionals in making efficient decisions while promoting mental well-being, its performance, robustness, and usability will be evaluated by a diverse group of users from various backgrounds and age groups. These users will be asked to install and use the application in their workplace. Since individuals experience emotions differently during decision-making, the application will collect personalized data regarding their emotional patterns and medical conditions before installation. This personalized data will help the application provide tailored outcomes for each user, rather than offering generic recommendations. A comparison of decision-making outcomes with and without using the twin-bot will validate the product’s real-world effectiveness.
Note: This project is still in the design phase.
Interested individuals are welcome to contact me for collaboration opportunities.